Limitation of ChatGPT in Causal Inference
In the realm of artificial intelligence, the ability to understand and reason about causality has always been a significant challenge. In a recent exchange on Twitter, Turing Prize Laureate Judea Pearl and AI enthusiast Jim Fan discussed the limitations of GPT, a state-of-the-art language model, in inferring causal relationships.
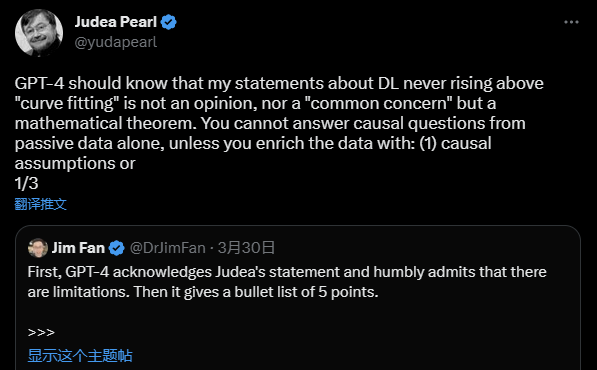
Judea Pearl's Critique
According to Judea Pearl, deep learning models like GPT are inherently limited in their ability to reason about causality. He argues that their achievements amount to little more than "curve fitting" and are constrained by the passive data they are trained on. Pearl posits that answering causal questions requires either causal assumptions or interventional experiments to enrich the data.
Jim Fan's Perspective
Jim Fan, on the other hand, highlights GPT's impressive performance in reasoning about "why" (cause and effect) and "what if" (counterfactual imagination). He suggests that GPT's ability to infer causality could be attributed to:
- The presence of causal examples and counterfactuals in the pre-training data.
- Inductive reasoning based on common sense.
- Language pattern matching.
- Heuristics applied to novel cases.
The Inherent Limitations of GPT
While GPT demonstrates some ability to reason about causality, it is important to recognize its inherent limitations. As an AI language model, GPT is unable to directly manipulate variables or actively collect new data to validate its causal inferences. Instead, it relies on the causal assumptions and human judgments present in its training data.
One example of this limitation can be seen in a hypothetical scenario where GPT is trained on a dataset containing the false statement: "Jumping from a building won't kill you because it's from the tenth floor." In this case, GPT might take this erroneous story as a causal assumption and generate incorrect inferences when answering related questions. Since GPT lacks the ability to interact with the real world and conduct interventional experiments, it cannot validate or correct its understanding of the causal relationship.
A Cautious Approach to Causal Inference
In light of these limitations, it is essential to exercise caution when using GPT or similar models for causal inference. To obtain more accurate results, it may be necessary to combine GPT's output with correct causal assumptions or conduct interventional experiments where possible.
In conclusion, the dialogue between Judea Pearl and Jim Fan serves as a valuable reminder of the limitations of deep learning models like GPT in the domain of causal inference. While these models have made significant strides in various aspects of natural language understanding, their abilities in causal reasoning remain constrained by their training data and the algorithms themselves.